Disaster or Not
CONCEPT
The ubiquitousness of smartphones enables people to announce an emergency they’re observing in real-time. Because of this, more agencies are interested in programatically monitoring Twitter (i.e. disaster relief organisations and news agencies). But, it’s not always clear whether a person’s words are actually announcing a disaster. Aim of this project is to build a machine learning model that predicts which Tweets are about real disasters and which one’s aren’t.
DATA
Each sample in the data has the following information:
- The text of a tweet
- A keyword from that tweet (although this may be blank!)
-
The location the tweet was sent from (may also be blank)
PROCESS
The development of a predictive model has involved the implementation of the following procedural steps:
- Data Cleaning: The tweets underwent multiple rounds of cleaning, encompassing tasks such as removing punctuations and eliminating non-English words.
- Data Preparation: Tweets have been vectorized and split into training and test sets.
- Model Implementation: A Naive Bayes model has been successfully implemented for the task, achieving a test accuracy of 78%.
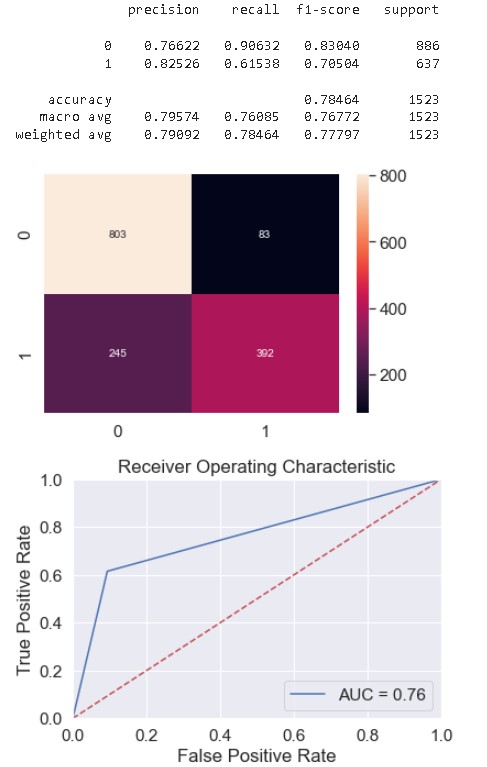
XGBoost evaluation
Document-Term Matrix for not a disaster

Document-Term Matrix for a disaster