OpenAI Gym
CONCEPT
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. It offers a standardised platform with predefined environments, such as games and simulations, where agents learn to make decisions by interacting with the environment. The agent receives feedback in the form of observations and rewards, aiming to maximise cumulative rewards over time. Gym provides a consistent interface for defining environments, actions, and observations, making it easy to experiment with and compare different reinforcement learning approaches.
Training Pipeline:
- Random Action: In the early stages of training, the agent takes random actions to explore the environment and populate its Q-table.
- Calculate Reward and Expected Reward: The agent interacts with the environment by taking actions, receiving rewards, and updating its Q-table. It calculates the reward for each action and estimates the expected reward for all possible actions in the current state.
- repeat until session time is over
- Repeat Until Session Time is Over: The exploration-exploitation loop continues until the predefined session time is over. The agent refines its policy over multiple episodes, gradually shifting from random actions to exploiting the learned Q-values.
Q-Learning Algorithm:
- Initialisation: The agent initialises its Q-table, which represents the state-action space, with arbitrary values. This Q-table is gradually updated through the learning process.
- Exploration-Exploitation Strategy: Q-Learning employs an exploration-exploitation strategy to balance the agent's exploration of the game environment and exploitation of learned knowledge. The agent randomly selects actions during the initial phase to explore the environment.
- Q-Table Update: After each action, the Q-table is updated based on the observed reward and the difference between the expected and actual Q-values. The learning rate influences the magnitude of these updates.
LunarLander v2 performance after Q-Learning implementation
Github repository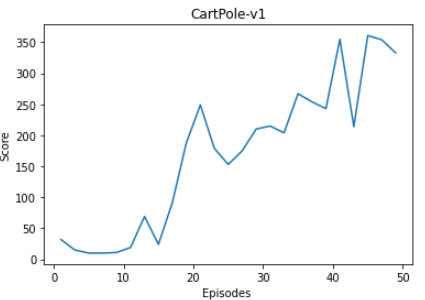
Model performance in CartPole v1 environment
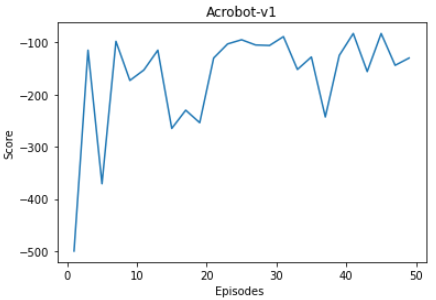
Model performance in Acrobot v1 environment
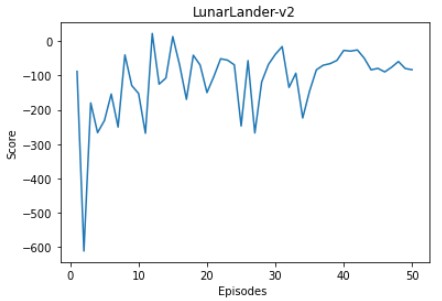
Model performance in LunarLander v2 environment